

How MCP Turns Your IDP into an Actual Teammate
Tired of TicketOps? Here’s how to break free.

Your runbooks live in wikis. Your SLOs live in monitoring dashboards. Your approval workflows live in ticketing systems. And you, the developer who actually needs to ship things, you’re stuck stitching all of this together manually, one step at a time.
This is where most cloud teams still operate. And it’s exhausting.
I realized this after our AI-Powered Platform Engineering workshop last week.
If you were there, you know it was packed. We had George Hantzaras (Director of Engineering, MongoDB) and Ajay Chankramath (Founder, Platformetrics) up there walking through how AI, golden paths, and internal developer platforms are completely reshaping the way modern teams ship software. The energy in the session was incredible. And the conversations didn’t stop when the session ended.
But here’s the thing that stuck with me the most:
MCP (Model Context Protocol) turns your platform into something an AI can actually do things with, not just talk about.
This is the difference between TicketOps and brittle runbooks versus workflows like provisioning, rolling back, and scaling that become assistant-triggered actions with guardrails and full visibility into what’s happening. Your AI goes from being a really smart search engine to being an actual teammate.
That’s the jump I think a lot of us have been waiting for.
So in this issue, I’m going to dig into what that actually looks like, and give you a practical starter pack you can adapt to your own stack. Because if you’ve been wondering how to move from AI as “a chat window” to AI as “a teammate who actually does the work,” this is a good place to start.
Cheers,
Editor-in-Chief
The Problem We’re All Facing
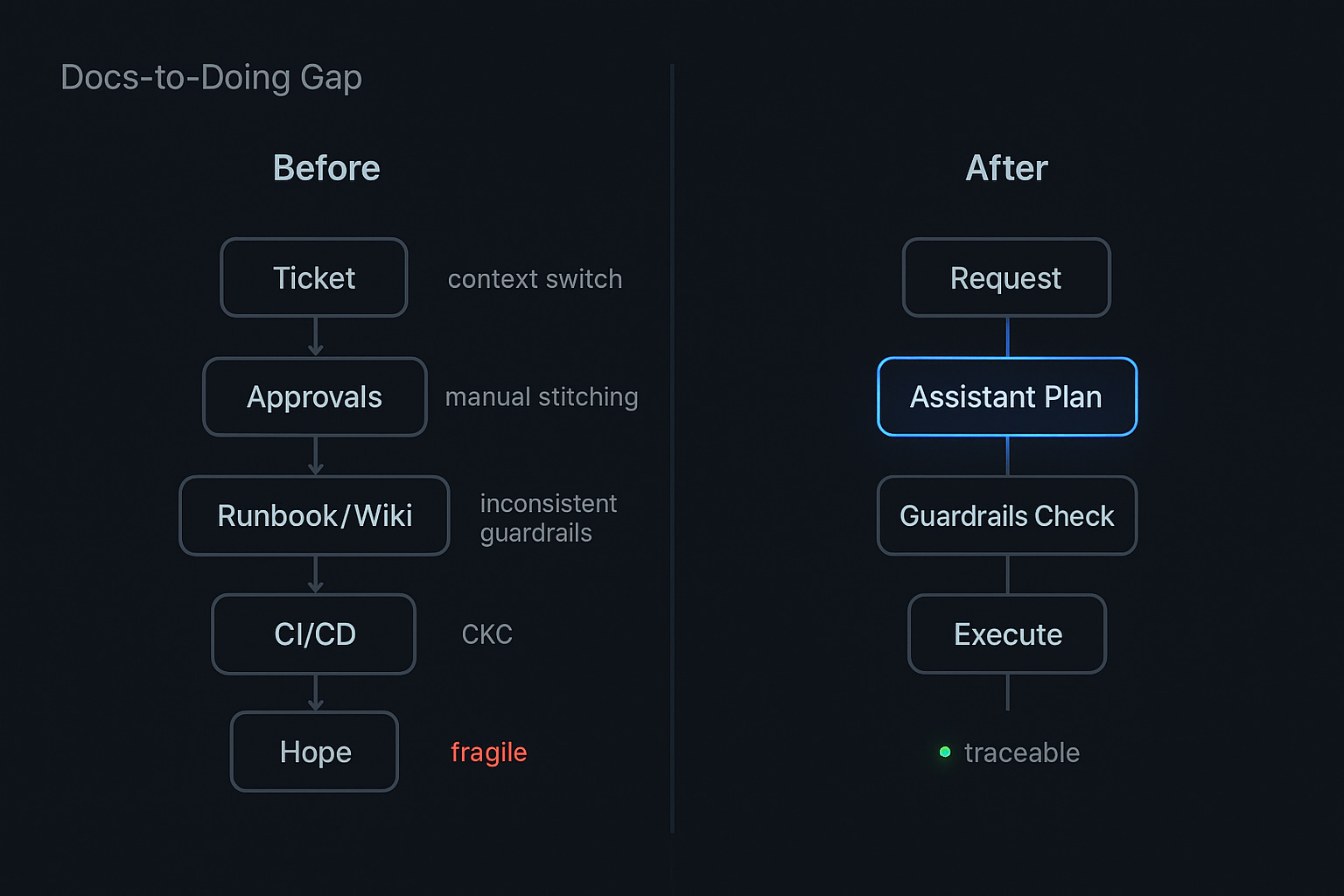
Let me paint a picture of how most cloud teams still operate today. You write a ticket. You wait for approvals. You hunt through runbooks to find the right commands to copy-paste. You watch CI/CD spin up. You cross your fingers that the safety nets catch anything that could go wrong.
Documentation and internal portals help you find things, sure. But they rarely do things. That gap, between knowing what to do and actually doing it, creates this constant context switching, slow feedback loops, and inconsistent safety guardrails.
The result is messy. Really messy. Brittle handoffs. Workflows duplicated across teams. And what should be “golden paths” that empower teams end up becoming “golden cages” that block velocity instead of enabling it.
Here’s what I think is the real core issue: we’ve separated knowledge from action. Your runbooks live in wikis. Your SLOs live in monitoring dashboards. Your approval workflows live in ticketing systems. And your developers, the people who actually need to ship things, they’re stuck stitching all of this together manually, one step at a time.
This friction doesn’t just slow shipping down. It creates inconsistency. One team deploys with proper approvals; another skips them. One team checks SLO impact before scaling; another scales blind. You end up with fragmented practices across your org, and nobody likes that.
We need a different model. Instead of “read the docs, then run the steps,” we should be asking our systems: “propose a plan, then execute it with guardrails.”
Here’s What Changed:
The solution rests on two foundational ideas working together, and honestly, the way they complement each other is elegant.
First: golden paths. These reduce decision fatigue without sacrificing flexibility. Think of a golden path as an end-to-end workflow with sensible defaults, something like: stateless service → preview environment → automated checks → production. These paths capture your team’s collective knowledge about how to do things safely. But they’re not straightjackets. You build in escape hatches for the 20% of cases that don’t fit the mold. Golden paths let you standardize without fossilizing your processes, and they’re the antidote to “TicketOps.”
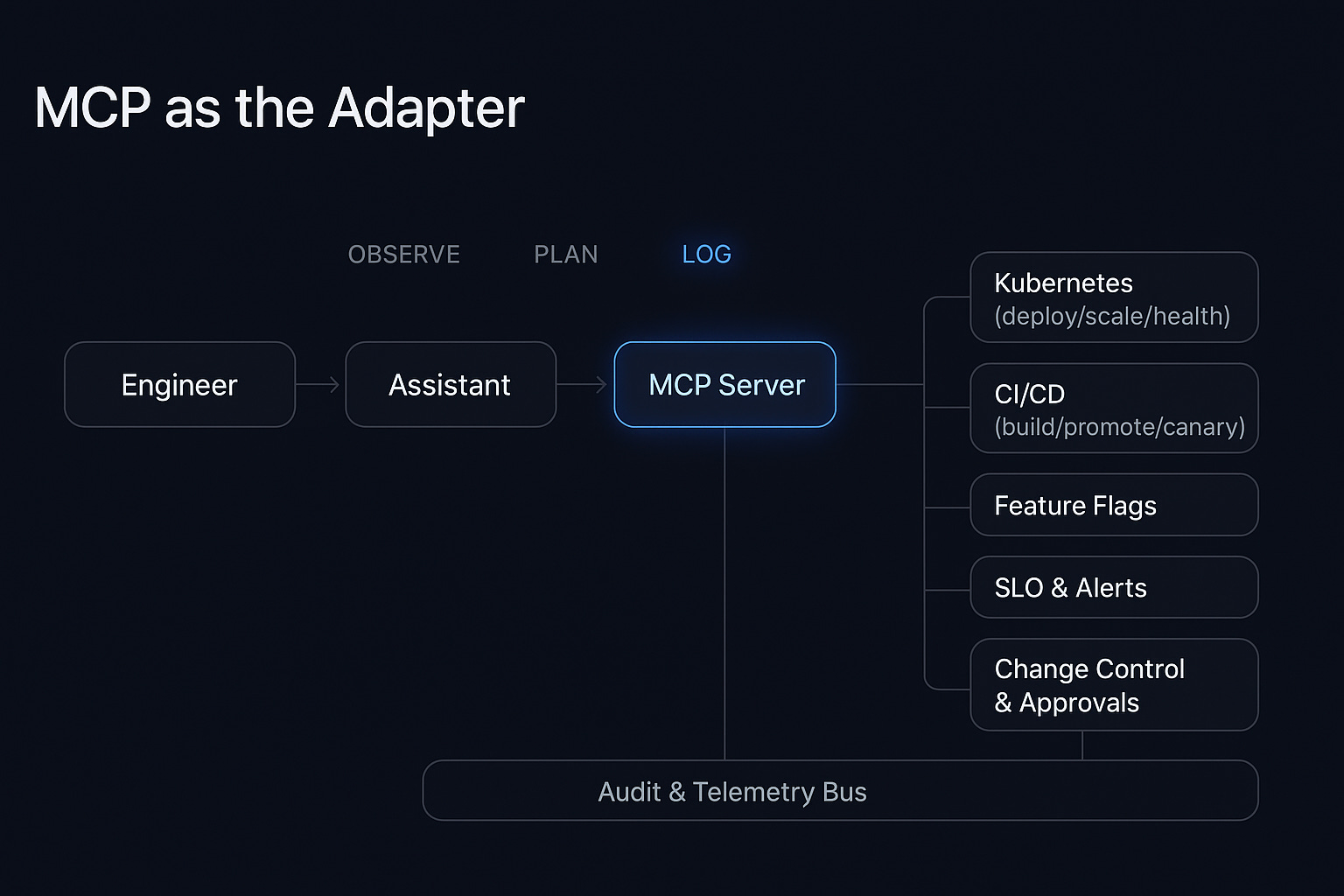
Second: the Model Context Protocol (MCP). This is the glue that makes it all work. MCP is a standard that exposes your golden paths as tools that an AI assistant can actually call. Think of it as an adapter layer between your assistant and your platform. The assistant can observe your systems: what services exist, what their SLOs are, what incidents are open right now. It can propose a plan (“I’ll deploy this to preview, run tests, then promote to prod”). And it can execute approved actions while logging everything for audit and observability. MCP turns your platform into a set of composable, auditable operations.
Here’s what this looks like in the real world. An engineer types: “Spin up a preview environment and load our staging data.”
The assistant gathers context. What’s the service’s dependency tree? What are the current SLO baselines? Who owns this service? What recent incidents or postmortems should I know about? It drafts a plan that respects your runbooks and standards. It shows you the diffs and policy checks that apply. Then it either executes immediately (low-risk actions) or routes to the right approver (medium/high-risk actions). Everything gets logged.
This isn’t theoretical anymore. It works.
How You Actually Build This
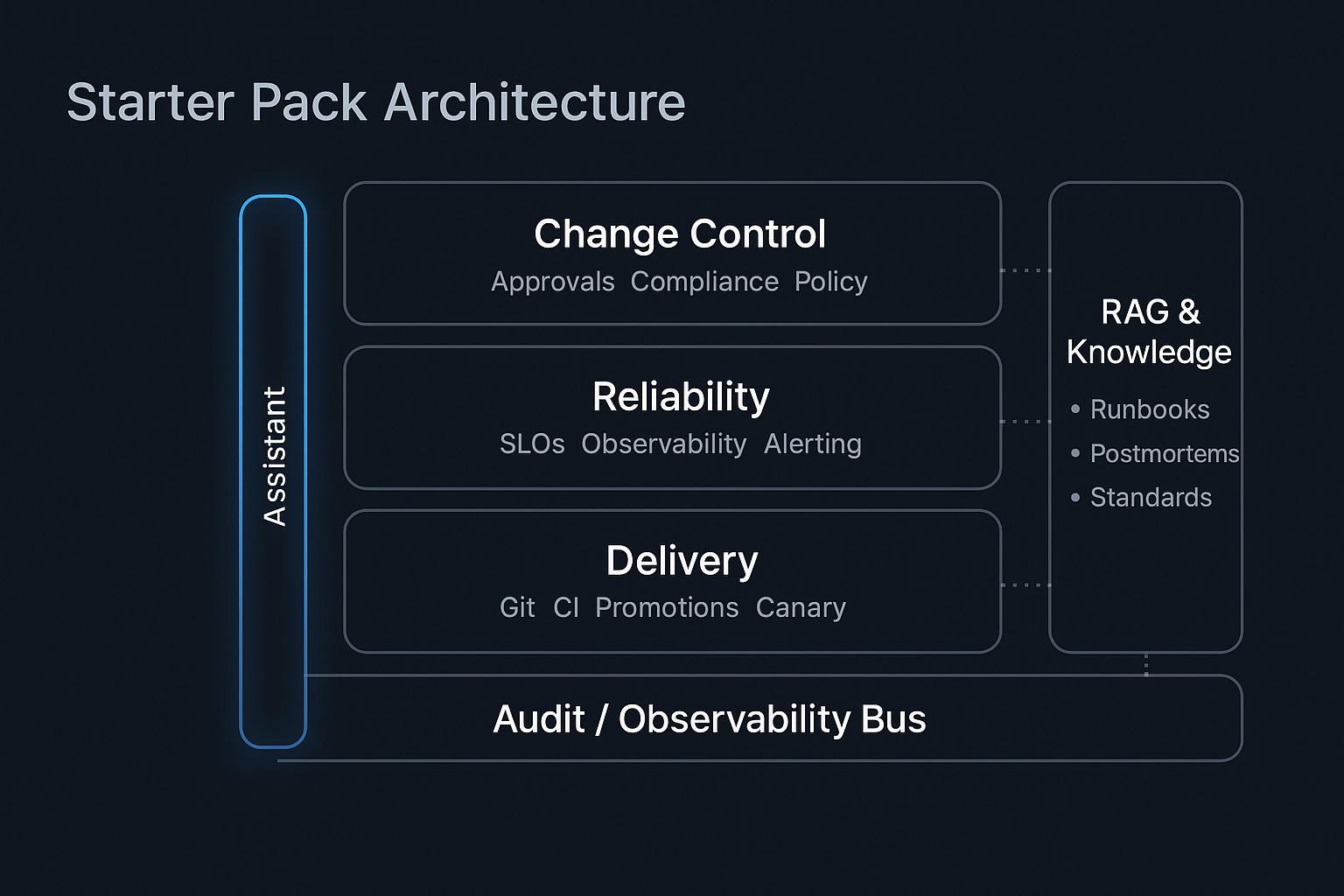
The architecture starts simple: pick one golden path. One high-value workflow, like service deployment, that you want to standardize.
Next, you build MCP servers that act as adapters to your existing systems. Your runtime layer exposes Kubernetes operations (deploy, scale, health checks) and feature flags as callable tools. Your delivery layer connects to Git, GitHub Actions, or GitLab CI to handle builds, promotions, and canary deployments. Your reliability layer taps into SLO systems, alerting platforms, and observability tools so the assistant can query metrics, create SLOs, and mute alerts with proper context. Your change control layer enforces approvals and integrates with compliance workflows.
Underneath all of this runs retrieval-augmented generation (RAG). Before the assistant proposes any action, it indexes and searches your runbooks, compliance standards, postmortems, and architectural guidelines. The plan that comes back doesn’t just say “deploy the service”, it references your procedures. “Deploy using our standard blue-green pattern [link to runbook]. SLO impact: +2% latency at p99 (within budget). Dependencies: notify the data team [link to postmortem]. Policy check: OK, proceed.”
Safety gets enforced as policy-as-code, not friction. You define risk tiers: low-risk actions (like querying logs) auto-execute. Medium-risk actions (like scaling a service) require human approval. High-risk actions (like deleting a database) are blocked unless routed through a formal approval path. Standards violations get auto-fixed when confidence is high, or escalated when not. Everything is logged.
The user experience ties it all together. An engineer uses chat or a slash command to describe what they need. The assistant gathers context from your systems and knowledge base, drafts a plan with full diffs and impact estimates, shows what policy checks apply, and executes: staying in the loop for decisions that matter (approvals, tradeoffs) but handling the rote work. Everything that happened gets logged: the initial request, the plan, who approved it, what actually ran, what the outcome was.
The Real Payoff

Over time, this architecture unifies your platform. Your internal developer platform (IDP) becomes more than a portal where people click and read documentation. It becomes an actor that moves with your engineers, understanding context, respecting guardrails, and turning workflows into outcomes.
You measure it differently too. Not by pageviews to your portal, but by lead time to production. By mean time to recovery when things break. By consistency of safety across teams. You tie actions to business impact: AI-assisted scaling and predictive capacity planning can deliver up to 25% cost optimization while keeping SLOs intact.
The shift from ticket-based workflows to action-based workflows with AI assistance and policy-driven safety doesn’t happen overnight. Start with one golden path. Build the MCP adapters for one system at a time. Add guardrails incrementally. But the direction is clear.
Push intelligence and safety down into your platform so that doing the right thing becomes the easy thing. And the hard work, decision-making, tradeoff analysis, exception handling, stays where it belongs: with your engineers.
That’s where we’re headed. And honestly? I think it’s going to change how we all work.